

This post is part of our Scaling Kubernetes Series. Register to watch live or access the recording, and check out our other posts in this series:
One interesting challenge with Kubernetes is deploying workloads across several regions. While you can technically have a cluster with several nodes located in different regions, this is generally regarded as something you should avoid due to the extra latency.
A popular alternative is to deploy a cluster for each region and find a way to orchestrate them.
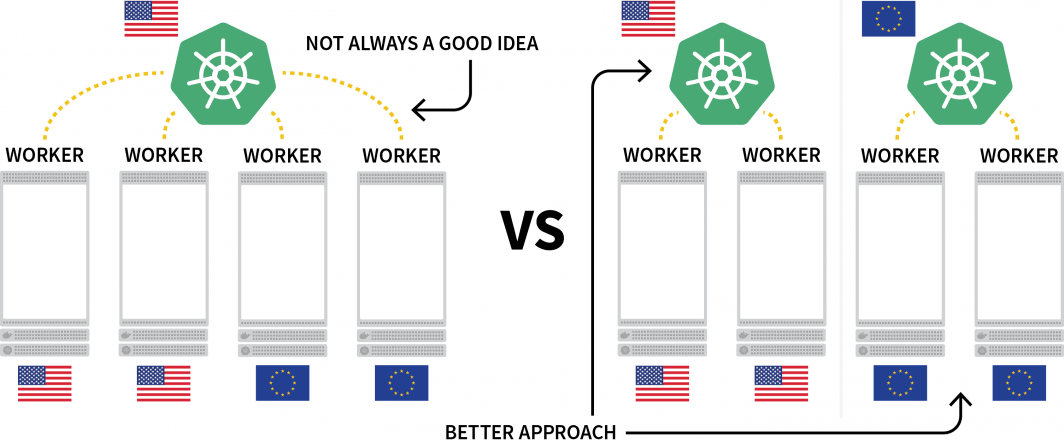
In this post, you will:
- Create three clusters: one in North America, one in Europe, and one in South East Asia.
- Create a fourth cluster that will act as an orchestrator for the others.
- Set up a single network out of the three cluster networks for seamless communication.
This post has been scripted to work with Terraform requiring minimal interaction. You can find the code for that on the LearnK8s GitHub.
Creating the Cluster Manager
Let’s start with creating the cluster that will manage the rest. The following commands can be used to create the cluster and save the kubeconfig file.
bash
$ linode-cli lke cluster-create \
--label cluster-manager \
--region eu-west \
--k8s_version 1.23
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig-cluster-managerYou can verify that the installation is successful with:
bash
$ kubectl get pods -A --kubeconfig=kubeconfig-cluster-managerExcellent!
In the cluster manager, you will install Karmada, a management system that enables you to run your cloud-native applications across multiple Kubernetes clusters and clouds. Karmada has a control plane installed in the cluster manager and the agent installed in every other cluster.
The control plane has three components:
- An API Server;
- A Controller Manager; and
- A Scheduler
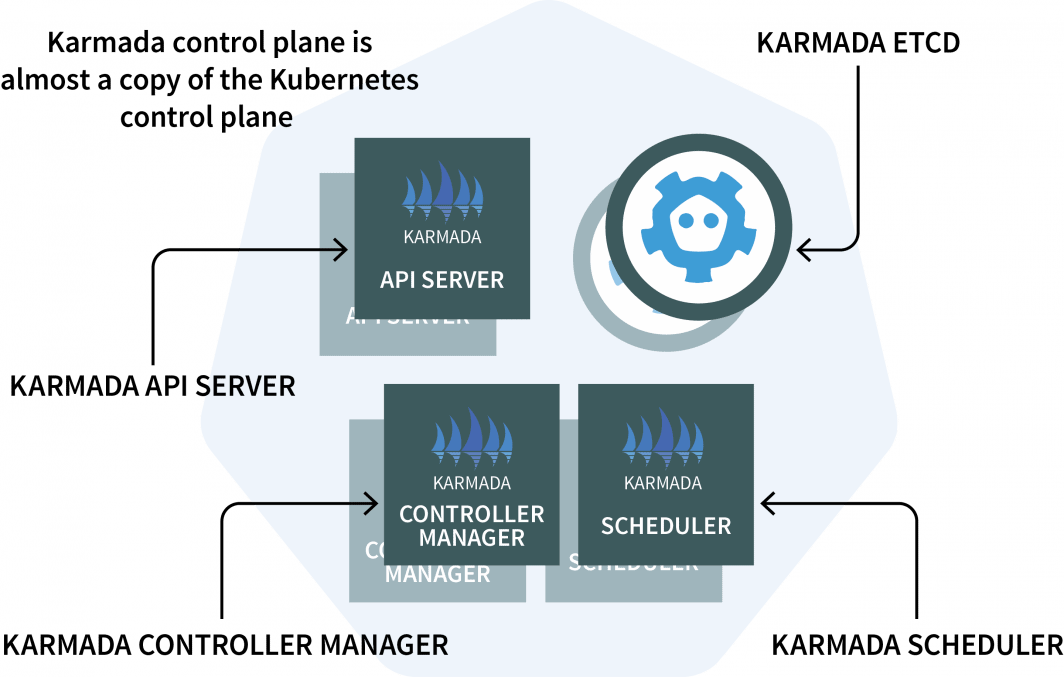
If those look familiar, it’s because the Kubernetes control plane features the same components! Karmada had to copy and augment them to work with multiple clusters.
That’s enough theory. Let’s get to the code.
You will use Helm to install the Karmada API server. Let’s add the Helm repository with:
bash
$ helm repo add karmada-charts https://raw.githubusercontent.com/karmada-io/karmada/master/charts
$ helm repo list
NAME URL
karmada-charts https://raw.githubusercontent.com/karmada-io/karmada/master/chartsSince the Karmada API server has to be reachable by all other clusters, you will have to
- expose it from the node; and
- make sure that the connection is trusted.
So let’s retrieve the IP address of the node hosting the control plane with:
bash
kubectl get nodes -o jsonpath='{.items[0].status.addresses[?(@.type==\"ExternalIP\")].address}' \
--kubeconfig=kubeconfig-cluster-managerNow you can install the Karmada control plane with:
bash
$ helm install karmada karmada-charts/karmada \
--kubeconfig=kubeconfig-cluster-manager \
--create-namespace --namespace karmada-system \
--version=1.2.0 \
--set apiServer.hostNetwork=false \
--set apiServer.serviceType=NodePort \
--set apiServer.nodePort=32443 \
--set certs.auto.hosts[0]="kubernetes.default.svc" \
--set certs.auto.hosts[1]="*.etcd.karmada-system.svc.cluster.local" \
--set certs.auto.hosts[2]="*.karmada-system.svc.cluster.local" \
--set certs.auto.hosts[3]="*.karmada-system.svc" \
--set certs.auto.hosts[4]="localhost" \
--set certs.auto.hosts[5]="127.0.0.1" \
--set certs.auto.hosts[6]="<insert the IP address of the node>"Once the installation is complete, you can retrieve the kubeconfig to connect to the Karmada API with:
bash
kubectl get secret karmada-kubeconfig \
--kubeconfig=kubeconfig-cluster-manager \
-n karmada-system \
-o jsonpath={.data.kubeconfig} | base64 -d > karmada-configBut wait, why another kubeconfig file?
The Karmada API is designed to replace the standard Kubernetes API but still retains all the functionality you are used to. In other words, you can create deployments that span multiple clusters with kubectl.
Before testing the Karmada API and kubectl, you should patch the kubeconfig file. By default, the generated kubeconfig can only be used from within the cluster network.
However, you can replace the following line to make it work:
yaml
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTi…
insecure-skip-tls-verify: false
server: https://karmada-apiserver.karmada-system.svc.cluster.local:5443 # <- this works only in the cluster
name: karmada-apiserver
# truncatedReplace it with the node’s IP address that you retrieved earlier:
yaml
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTi…
insecure-skip-tls-verify: false
server: https://<node's IP address>:32443 # <- this works from the public internet
name: karmada-apiserver
# truncatedGreat, it’s time to test Karmada.
Installing the Karmada Agent
Issue the following command to retrieve all deployments and all clusters:
bash
$ kubectl get clusters,deployments --kubeconfig=karmada-config
No resources foundUnsurprisingly, there are no deployments and no additional clusters. Let’s add a few more clusters and connect them to the Karmada control plane.
Repeat the following commands three times:
bash
linode-cli lke cluster-create \
--label <insert-cluster-name> \
--region <insert-region> \
--k8s_version 1.23
linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig-<insert-cluster-name>The values should be the following:
- Cluster name
eu, regioneu-west and kubeconfig filekubeconfig-eu - Cluster name
ap, regionap-southand kubeconfig filekubeconfig-ap - Cluster name
us, regionus-westand kubeconfig filekubeconfig-us
You can verify that the clusters are created successfully with:
bash
$ kubectl get pods -A --kubeconfig=kubeconfig-eu
$ kubectl get pods -A --kubeconfig=kubeconfig-ap
$ kubectl get pods -A --kubeconfig=kubeconfig-usNow it’s time to make them join the Karmada cluster.
Karmada uses an agent on every other cluster to coordinate deployment with the control plane.
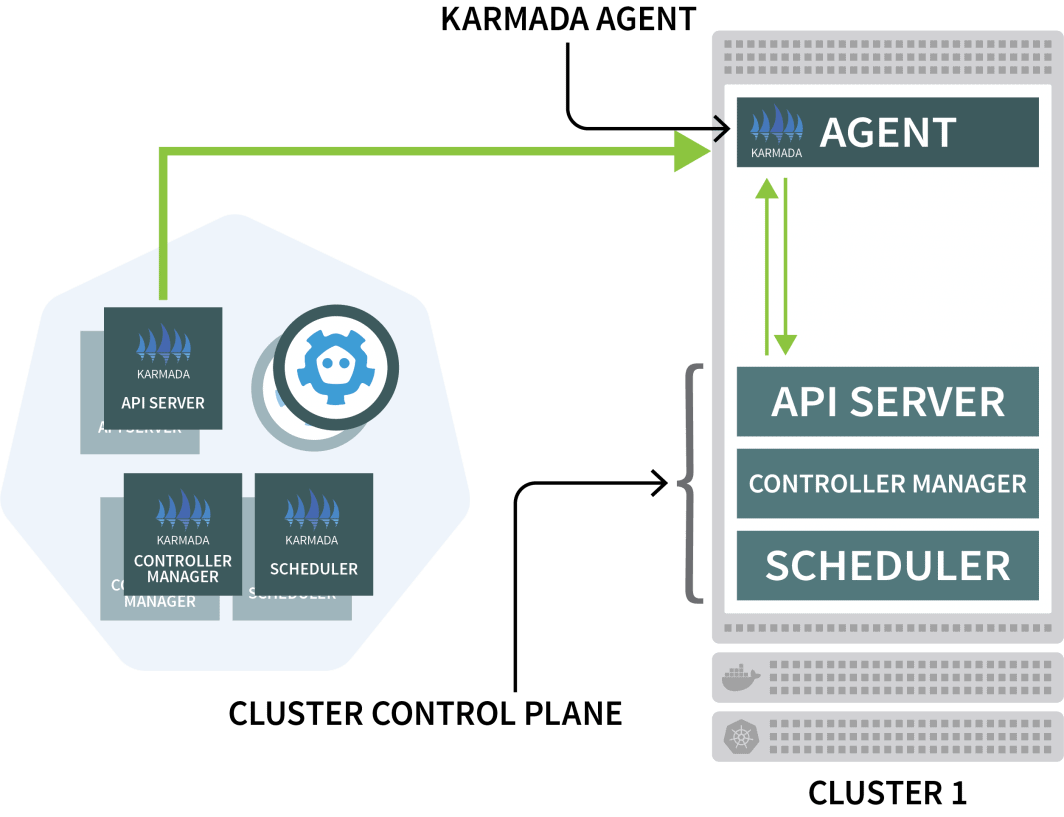
You will use Helm to install the Karmada agent and link it to the cluster manager:
bash
$ helm install karmada karmada-charts/karmada \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--create-namespace --namespace karmada-system \
--version=1.2.0 \
--set installMode=agent \
--set agent.clusterName=<insert-cluster-name> \
--set agent.kubeconfig.caCrt=<karmada kubeconfig certificate authority> \
--set agent.kubeconfig.crt=<karmada kubeconfig client certificate data> \
--set agent.kubeconfig.key=<karmada kubeconfig client key data> \
--set agent.kubeconfig.server=https://<insert node's IP address>:32443 \You will have to repeat the above command three times and insert the following variables:
- The cluster name. This is either
eu,ap, orus - The cluster manager’s certificate authority. You can find this value in the
karmada-configfileunder clusters[0].cluster['certificate-authority-data'].
You can decode the value from base64. - The user’s client certificate data. You can find this value in the
karmada-configfile underusers[0].user['client-certificate-data'].
You can decode the value from base64. - The user’s client certificate data. You can find this value in the
karmada-configfile underusers[0].user['client-key-data'].
You can decode the value from base64. - The IP address of the node hosting the Karmada control plane.
To verify that the installation is complete, you can issue the following command:
bash
$ kubectl get clusters --kubeconfig=karmada-config
NAME VERSION MODE READY
eu v1.23.8 Pull True
ap v1.23.8 Pull True
us v1.23.8 Pull TrueExcellent!
Orchestrating Multicluster Deployment with Karmada Policies
With the current configuration, you submit a workload to Karmada, which will then distribute it across the other clusters.
Let’s test this by creating a deployment:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello
spec:
replicas: 3
selector:
matchLabels:
app: hello
template:
metadata:
labels:
app: hello
spec:
containers:
- image: stefanprodan/podinfo
name: hello
---
apiVersion: v1
kind: Service
metadata:
name: hello
spec:
ports:
- port: 5000
targetPort: 9898
selector:
app: helloYou can submit the deployment to the Karmada API server with:
bash
$ kubectl apply -f deployment.yaml --kubeconfig=karmada-configThis deployment has three replicas– will those distribute equally across the three clusters?
Let’s check:
bash
$ kubectl get deployments --kubeconfig=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 0/3 0 0Why is Karmada not creating the Pods?
Let’s describe the deployment:
bash
$ kubectl describe deployment hello --kubeconfig=karmada-config
Name: hello
Namespace: default
Selector: app=hello
Replicas: 3 desired | 0 updated | 0 total | 0 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Events:
Type Reason From Message
---- ------ ---- -------
Warning ApplyPolicyFailed resource-detector No policy match for resourceKarmada doesn’t know what to do with the deployments because you haven’t specified a policy.
The Karmada scheduler uses policies to allocate workloads to clusters.
Let’s define a simple policy that assigns a replica to each cluster:
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 1
- targetCluster:
clusterNames:
- ap
weight: 1
- targetCluster:
clusterNames:
- eu
weight: 1You can submit the policy to the cluster with:
bash
$ kubectl apply -f policy.yaml --kubeconfig=karmada-configLet’s inspect the deployments and pods:
bash
$ kubectl get deployments --kubeconfig=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 3/3 3 3
$ kubectl get pods --kubeconfig=kubeconfig-eu
NAME READY STATUS RESTARTS
hello-5d857996f-hjfqq 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-ap
NAME READY STATUS RESTARTS
hello-5d857996f-xr6hr 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-us
NAME READY STATUS RESTARTS
hello-5d857996f-nbz48 1/1 Running 0
Karmada assigned a pod to each cluster because your policy defined an equal weight for each cluster.
Let’s scale the deployment to 10 replicas with:
bash
$ kubectl scale deployment/hello --replicas=10 --kubeconfig=karmada-configIf you inspect the pods, you might find the following:
bash
$ kubectl get deployments --kubeconfig=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 10/10 10 10
$ kubectl get pods --kubeconfig=kubeconfig-eu
NAME READY STATUS RESTARTS
hello-5d857996f-dzfzm 1/1 Running 0
hello-5d857996f-hjfqq 1/1 Running 0
hello-5d857996f-kw2rt 1/1 Running 0
hello-5d857996f-nz7qz 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-ap
NAME READY STATUS RESTARTS
hello-5d857996f-pd9t6 1/1 Running 0
hello-5d857996f-r7bmp 1/1 Running 0
hello-5d857996f-xr6hr 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-us
NAME READY STATUS RESTARTS
hello-5d857996f-nbz48 1/1 Running 0
hello-5d857996f-nzgpn 1/1 Running 0
hello-5d857996f-rsp7k 1/1 Running 0Let’s amend the policy so that the EU and US clusters hold 40% of the pods and only 20% is left to the AP cluster.
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 2
- targetCluster:
clusterNames:
- ap
weight: 1
- targetCluster:
clusterNames:
- eu
weight: 2You can submit the policy with:
bash
$ kubectl apply -f policy.yaml --kubeconfig=karmada-configYou can observe the distribution of your pod changing accordingly:
bash
$ kubectl get pods --kubeconfig=kubeconfig-eu
NAME READY STATUS RESTARTS AGE
hello-5d857996f-hjfqq 1/1 Running 0 6m5s
hello-5d857996f-kw2rt 1/1 Running 0 2m27s
$ kubectl get pods --kubeconfig=kubeconfig-ap
hello-5d857996f-k9hsm 1/1 Running 0 51s
hello-5d857996f-pd9t6 1/1 Running 0 2m41s
hello-5d857996f-r7bmp 1/1 Running 0 2m41s
hello-5d857996f-xr6hr 1/1 Running 0 6m19s
$ kubectl get pods --kubeconfig=kubeconfig-us
hello-5d857996f-nbz48 1/1 Running 0 6m29s
hello-5d857996f-nzgpn 1/1 Running 0 2m51s
hello-5d857996f-rgj9t 1/1 Running 0 61s
hello-5d857996f-rsp7k 1/1 Running 0 2m51s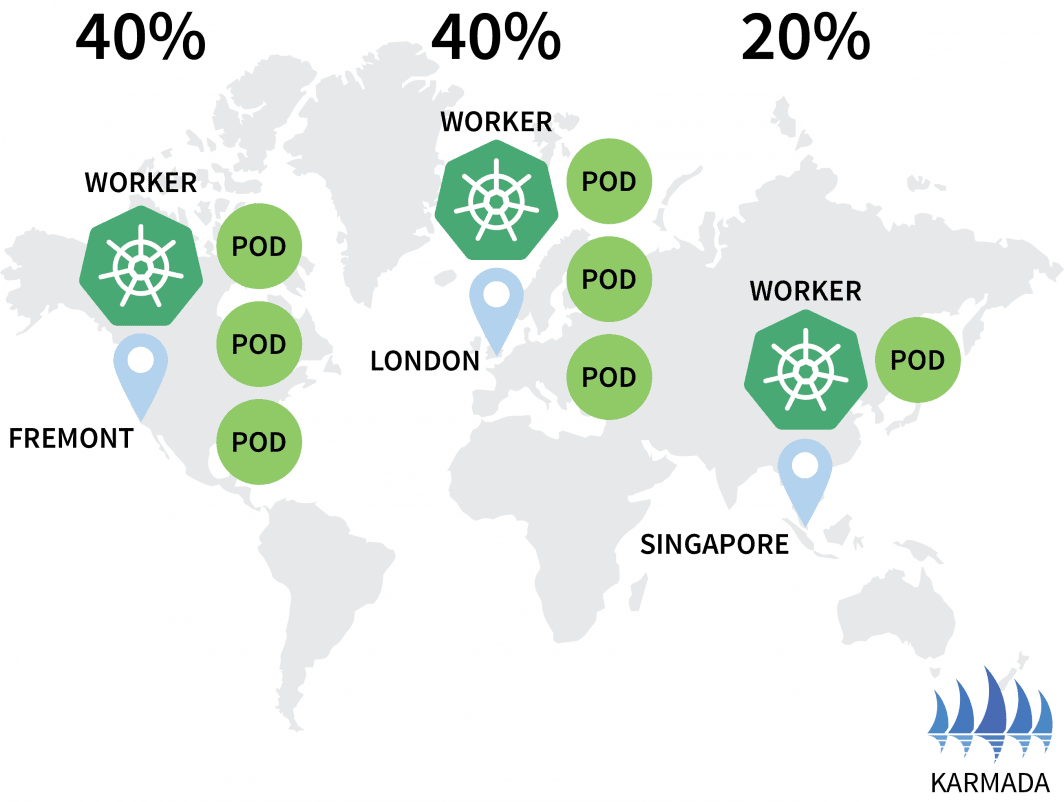
Great!
Karmada supports several policies to distribute your workloads. You can check out the documentation for more advanced use cases.
The pods are running in the three clusters, but how can you access them?
Let’s inspect the service in Karmada:
bash
$ kubectl describe service hello --kubeconfig=karmada-config
Name: hello
Namespace: default
Labels: propagationpolicy.karmada.io/name=hello-propagation
propagationpolicy.karmada.io/namespace=default
Selector: app=hello
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.105.24.193
IPs: 10.105.24.193
Port: <unset> 5000/TCP
TargetPort: 9898/TCP
Events:
Type Reason Message
---- ------ -------
Normal SyncSucceed Successfully applied resource(default/hello) to cluster ap
Normal SyncSucceed Successfully applied resource(default/hello) to cluster us
Normal SyncSucceed Successfully applied resource(default/hello) to cluster eu
Normal AggregateStatusSucceed Update resourceBinding(default/hello-service) with AggregatedStatus successfully.
Normal ScheduleBindingSucceed Binding has been scheduled
Normal SyncWorkSucceed Sync work of resourceBinding(default/hello-service) successful.The service is deployed in all three clusters, but they aren’t connected.
Even if Karmada can manage several clusters, it does not provide any networking mechanism to make sure that the three clusters are linked. In other words, Karmada is an excellent tool to orchestrate deployments across clusters, but you need something else to make sure those clusters can communicate with each other.
Connecting Multi Clusters with Istio
Istio is usually used to control the network traffic between applications in the same cluster. It works by intercepting all outgoing and incoming requests and proxying them through Envoy.
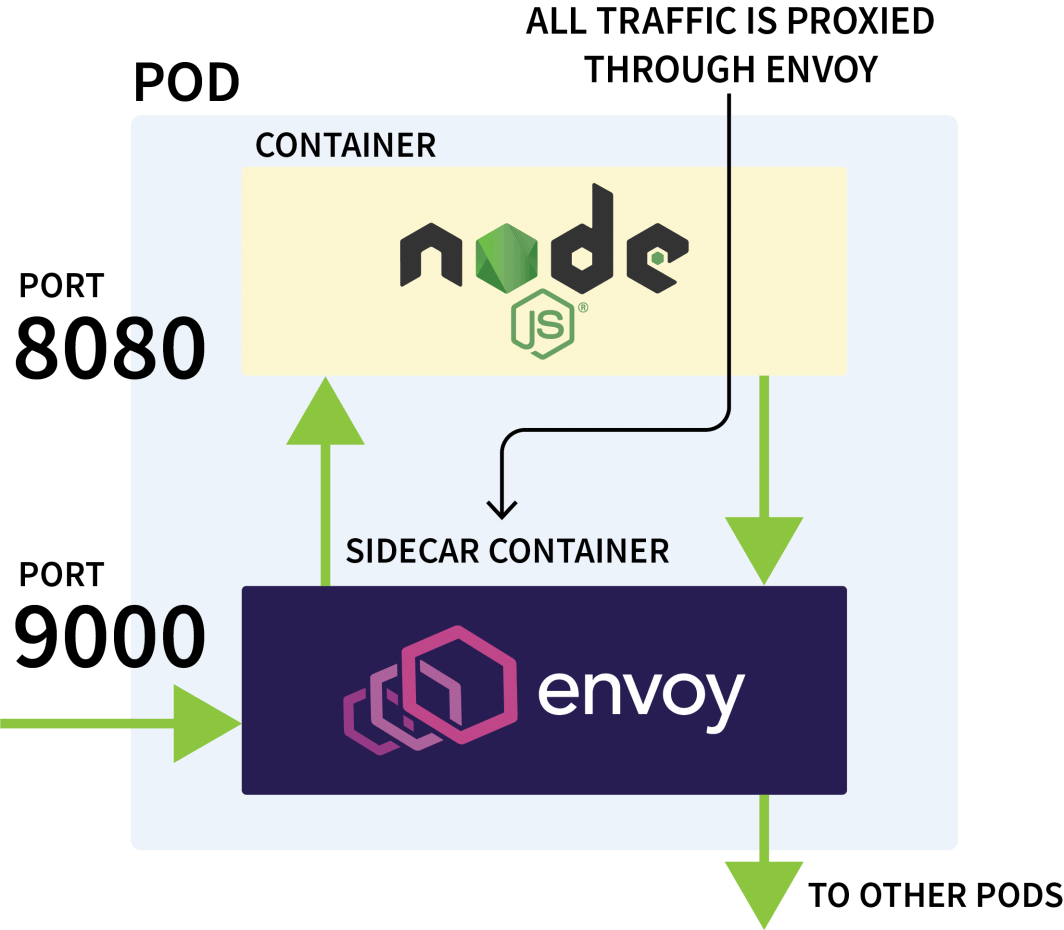
The Istio control plane is in charge of updating and collecting metrics from those proxies and can also issue instructions to divert the traffic.
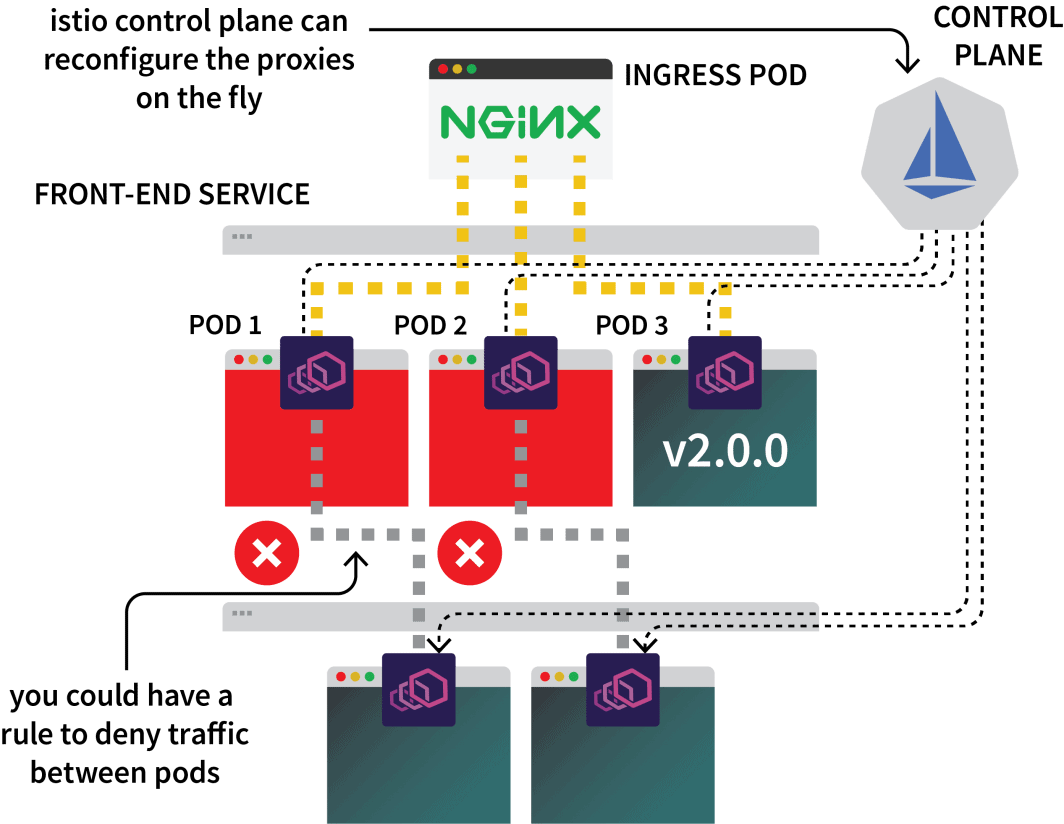
So you could use Istio to intercept all the traffic to a particular service and direct it to one of the three clusters. That’s the idea with Istio multicluster setup.
That’s enough theory– let’s get our hands dirty. The first step is to install Istio in the three clusters.
While there are several ways to install Istio, I usually prefer Helm:
bash
$ helm repo add istio https://istio-release.storage.googleapis.com/charts
$ helm repo list
NAME URL
istio https://istio-release.storage.googleapis.com/chartsYou can install Istio in the three clusters with:
bash
$ helm install istio-base istio/base \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--create-namespace --namespace istio-system \
--version=1.14.1You should replace the cluster-name with ap, eu and us and execute the command for each.
The base chart installs mostly common resources, such as Roles and RoleBindings.
The actual installation is packaged in the istiod chart. But before you proceed with that, you have to configure the Istio Certificate Authority (CA) to make sure that the three clusters can connect and trust each other.
In a new directory, clone the Istio repository with:
bash
$ git clone https://github.com/istio/istioCreate a certs folder and change to that directory:
bash
$ mkdir certs
$ cd certsCreate the root certificate with:
bash
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk root-caThe command generated the following files:
root-cert.pem: the generated root certificateroot-key.pem: the generated root keyroot-ca.conf: the configuration for OpenSSL to generate the root certificateroot-cert.csr: the generated CSR for the root certificate
For each cluster, generate an intermediate certificate and key for the Istio Certificate Authority:
bash
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster1-cacerts
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster2-cacerts
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster3-cacertsThe commands will generate the following files in a directory named cluster1, cluster2, and cluster3:
bash
$ kubectl create secret generic cacerts -n istio-system \
--kubeconfig=kubeconfig-<cluster-name>
--from-file=<cluster-folder>/ca-cert.pem \
--from-file=<cluster-folder>/ca-key.pem \
--from-file=<cluster-folder>/root-cert.pem \
--from-file=<cluster-folder>/cert-chain.pemYou should execute the commands with the following variables:
| cluster name | folder name |
| :----------: | :---------: |
| ap | cluster1 |
| us | cluster2 |
| eu | cluster3 |With those done, you are finally ready to install istiod:
bash
$ helm install istiod istio/istiod \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--namespace istio-system \
--version=1.14.1 \
--set global.meshID=mesh1 \
--set global.multiCluster.clusterName=<insert-cluster-name> \
--set global.network=<insert-network-name>You should repeat the command three times with the following variables:
| cluster name | network name |
| :----------: | :----------: |
| ap | network1 |
| us | network2 |
| eu | network3 |You should also tag the Istio namespace with a topology annotation:
bash
$ kubectl label namespace istio-system topology.istio.io/network=network1 --kubeconfig=kubeconfig-ap
$ kubectl label namespace istio-system topology.istio.io/network=network2 --kubeconfig=kubeconfig-us
$ kubectl label namespace istio-system topology.istio.io/network=network3 --kubeconfig=kubeconfig-euIs that all?
Almost.
Tunneling Traffic with an East-West Gateway
You still need:
- a gateway to funnel the traffic from one cluster to the other; and
- a mechanism to discover IP addresses in other clusters.
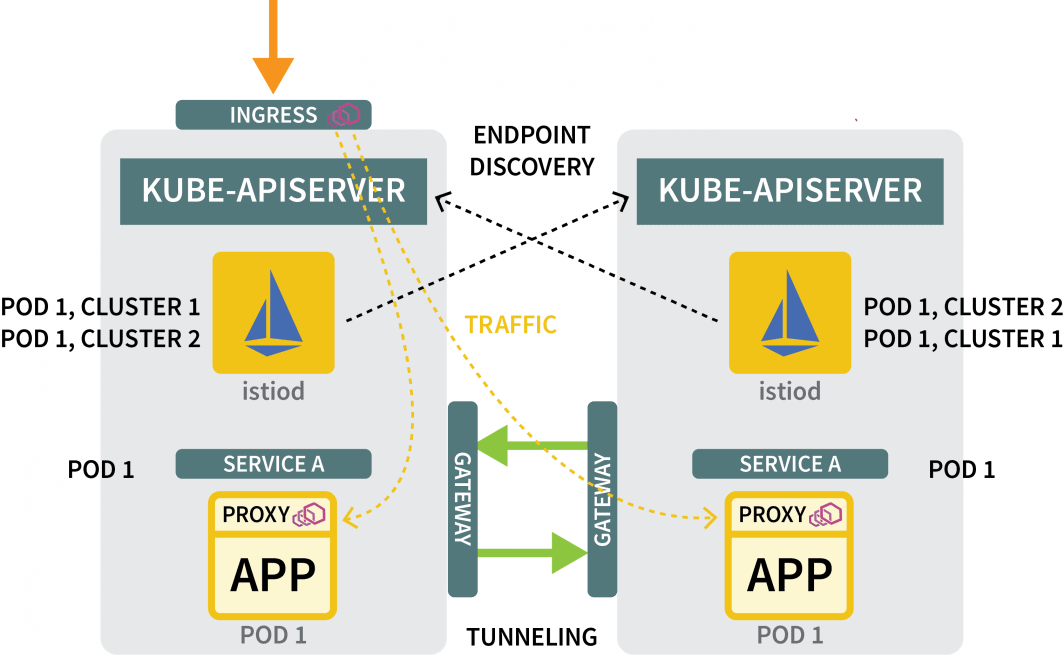
For the gateway, you can use Helm to install it:
bash
$ helm install eastwest-gateway istio/gateway \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--namespace istio-system \
--version=1.14.1 \
--set labels.istio=eastwestgateway \
--set labels.app=istio-eastwestgateway \
--set labels.topology.istio.io/network=istio-eastwestgateway \
--set labels.topology.istio.io/network=istio-eastwestgateway \
--set networkGateway=<insert-network-name> \
--set service.ports[0].name=status-port \
--set service.ports[0].port=15021 \
--set service.ports[0].targetPort=15021 \
--set service.ports[1].name=tls \
--set service.ports[1].port=15443 \
--set service.ports[1].targetPort=15443 \
--set service.ports[2].name=tls-istiod \
--set service.ports[2].port=15012 \
--set service.ports[2].targetPort=15012 \
--set service.ports[3].name=tls-webhook \
--set service.ports[3].port=15017 \
--set service.ports[3].targetPort=15017 \You should repeat the command three times with the following variables:
| cluster name | network name |
| :----------: | :----------: |
| ap | network1 |
| us | network2 |
| eu | network3 |Then for each cluster, expose a Gateway with the following resource:
yaml
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: cross-network-gateway
spec:
selector:
istio: eastwestgateway
servers:
- port:
number: 15443
name: tls
protocol: TLS
tls:
mode: AUTO_PASSTHROUGH
hosts:
- "*.local"You can submit the file to the clusters with:
bash
$ kubectl apply -f expose.yaml --kubeconfig=kubeconfig-eu
$ kubectl apply -f expose.yaml --kubeconfig=kubeconfig-ap
$ kubectl apply -f expose.yaml --kubeconfig=kubeconfig-usFor the discovery mechanisms, you need to share the credentials of each cluster. This is necessary because the clusters are not aware of each other.
To discover other IP addresses, they need to access other clusters and register those as possible destinations for the traffic. To do so, you must create a Kubernetes secret with the kubeconfig file for the other clusters.
Istio will use those to connect to the other clusters, discover the endpoints and instruct the Envoy proxies to forward the traffic.
You will need three secrets:
yaml
apiVersion: v1
kind: Secret
metadata:
labels:
istio/multiCluster: true
annotations:
networking.istio.io/cluster: <insert cluster name>
name: "istio-remote-secret-<insert cluster name>"
type: Opaque
data:
<insert cluster name>: <insert cluster kubeconfig as base64>You should create the three secrets with the following variables:
| cluster name | secret filename | kubeconfig |
| :----------: | :-------------: | :-----------: |
| ap | secret1.yaml | kubeconfig-ap |
| us | secret2.yaml | kubeconfig-us |
| eu | secret3.yaml | kubeconfig-eu |Now you should submit the secrets to the cluster paying attention to not submitting the AP secret to the AP cluster.
The commands should be the following:
bash
$ kubectl apply -f secret2.yaml -n istio-system --kubeconfig=kubeconfig-ap
$ kubectl apply -f secret3.yaml -n istio-system --kubeconfig=kubeconfig-ap
$ kubectl apply -f secret1.yaml -n istio-system --kubeconfig=kubeconfig-us
$ kubectl apply -f secret3.yaml -n istio-system --kubeconfig=kubeconfig-us
$ kubectl apply -f secret1.yaml -n istio-system --kubeconfig=kubeconfig-eu
$ kubectl apply -f secret2.yaml -n istio-system --kubeconfig=kubeconfig-euAnd that’s all!
You’re ready to test the setup.
Testing the Multicluster Networking
Let’s create a deployment for a sleep pod.
You will use this pod to make a request to the Hello deployment that you created earlier:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: sleep
spec:
selector:
matchLabels:
app: sleep
template:
metadata:
labels:
app: sleep
spec:
terminationGracePeriodSeconds: 0
containers:
- name: sleep
image: curlimages/curl
command: ["/bin/sleep", "3650d"]
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: /etc/sleep/tls
name: secret-volume
volumes:
- name: secret-volume
secret:
secretName: sleep-secret
optional: trueYou can create the deployment with:
bash
$ kubectl apply -f sleep.yaml --kubeconfig=karmada-configSince there is no policy for this deployment, Karmada will not process it and leave it pending. You can amend the policy to include the deployment with:
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
- apiVersion: apps/v1
kind: Deployment
name: sleep
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 2
- targetCluster:
clusterNames:
- ap
weight: 2
- targetCluster:
clusterNames:
- eu
weight: 1You can apply the policy with:
bash
$ kubectl apply -f policy.yaml --kubeconfig=karmada-configYou can figure out where the pod was deployed with:
bash
$ kubectl get pods --kubeconfig=kubeconfig-eu
$ kubectl get pods --kubeconfig=kubeconfig-ap
$ kubectl get pods --kubeconfig=kubeconfig-usNow, assuming the pod landed on the US cluster, execute the following command:
Now, assuming the pod landed on the US cluster, execute the following command:
bash
for i in {1..10}
do
kubectl exec --kubeconfig=kubeconfig-us -c sleep \
"$(kubectl get pod --kubeconfig=kubeconfig-us -l \
app=sleep -o jsonpath='{.items[0].metadata.name}')" \
-- curl -sS hello:5000 | grep REGION
doneYou might notice that the response comes from different pods from different regions!
Job done!
Where to go from here?
This setup is quite basic and lacks several more features that you probably want to incorporate:
- you could expose an Istio ingress from each cluster to ingest the traffic;
- you could use Istio to shape the traffic so that local traffic is preferred; and
- you might want to use Istio policy enforcement rules to define how the traffic can flow between the clusters.
To recap what we covered in this post:
- using Karmada to control several clusters;
- defining policy to schedule workloads across several clusters;
- using Istio to bridge the networking of multiple clusters; and
- how Istio intercepts the traffic and forwards it to other clusters.
You can see a full walkthrough of scaling Kubernetes across regions, in addition to other scaling methodologies, by registering for our webinar series and watching on-demand.




Comments