
 (1)")
Large language models (LLMs) are all the rage, especially with recent developments from OpenAI. The allure of LLMs comes from their ability to understand, interpret, and generate human language in a way that was once thought to be the exclusive domain of humans. Tools like CoPilot are quickly integrating into the everyday life of developers, while ChatGPT-fueled applications are becoming increasingly mainstream.
The popularity of LLMs also stems from their accessibility to the average developer. With many open-source models available, new tech startups appear daily with some sort of LLM-based solution to a problem.
Data has been referred to as the “new oil.” In machine learning, data serves as the raw material used to train, test, and validate models. High-quality, diverse, and representative data is essential for creating LLMs that are accurate, reliable, and robust.
Building your own LLM can be challenging, especially when it comes to collecting and storing data. Handling large volumes of unstructured data, along with storing it and managing access, are just some of the challenges you might face. In this post, we’ll explore these data management challenges. Specifically, we’ll look at:
- How LLMs work and how to select from existing models
- The types of data used in LLMs
- Data pipelines and ingestion for LLMs
Our goal is to give you a clear understanding of the critical role that data plays in LLMs, equipping you with the knowledge to manage data effectively in your own LLM projects.
To get started, let’s lay a basic foundation of understanding for LLMs.
How LLMs Work and How To Select from Existing Models
At a high level, an LLM works by converting words (or sentences) into numerical representations called embeddings. These embeddings capture the semantic meaning and relationships between words, allowing the model to understand language. For example, an LLM would learn that the words “dog” and “puppy” are related, and it would place them closer together in their numerical space, while the word “tree” would be more distant.

The most critical part of an LLM is the neural network, which is a computing model inspired by the human brain’s functioning. The neural network can learn these embeddings and their relationships from the data it is trained on. Like with most machine learning applications, LLM models need large amounts of data. Typically, with more data and higher-quality data for model training, the more accurate the model will be, meaning you’ll need a good method for managing the data for your LLMs.
Considerations When Weighing Existing Models
Fortunately for developers, many open-source options for LLMs are currently available, with several popular options that allow for commercial use, including:
- Dolly (released by Databricks)
- Open LLaMA (Meta reproduction)
- Many, many more
With such an extensive list to choose from, selecting the right open-source LLM model to use can be tricky. Understanding the compute and memory resources needed for an LLM model is important. The model size—for example, 3 billion parameters of input versus 7 billion—impacts the amount of resources you’ll need to run and exercise the model. Consider this against your capabilities. For example, several DLite models have been made available specifically to be run on laptops rather than requiring high-cost cloud resources.
When researching each LLM, it’s important to note how the model was trained and what kind of task it is generally geared toward. These distinctions will also affect your choice. Planning your LLM work will involve sifting through the open-source model options, understanding where each model shines best, and anticipating the resources you’ll need to use for each model.
Depending on the application or context in which you’ll need an LLM, you might start with an existing LLM or you might choose to train an LLM from scratch. With an existing LLM, you may use it as is, or you may fine-tune the model with additional data that’s representative of the task you have in mind.
Choosing the best approach for your needs requires a strong understanding of the data used for training LLMs.
The Types of Data Used in LLMs
When it comes to training an LLM, the data used is typically textual. However, the nature of this text data can vary widely, and understanding the different types of data that might be encountered is essential. In general, LLM data can be categorized into two types: semi-structured and unstructured data. Structured data, which is data represented in a tabular dataset, is unlikely to be used in LLMs.
Semi-Structured Data
Semi-structured data is organized in some predefined manner and follows a certain model. This organization allows for straightforward searching and querying of the data. In the context of LLMs, an example of semi-structured data might be a corpus of text in which each entry is associated with certain tags or metadata. Examples of semi-structured data include:
- News articles, with each associated with a category (such as sports, politics, or technology).
- Customer reviews, with each review associated with a rating and product information.
- Social media posts, with each post associated with the user who posted, the time of posting, and other metadata.
In these cases, an LLM might learn to predict the category based on the news article, the rating based on the review text, or the sentiment of a social media post based on its content.
Unstructured Data
Unstructured data, on the other hand, lacks a predefined organization or model. This data is often text-heavy and may also contain dates, numbers, and facts, making it more complicated to process and analyze. In the context of LLMs, unstructured data is very common. Examples of unstructured data include:
- Books, articles, and other long-form content
- Transcripts taken from interviews or podcasts
- Web pages or documents
Without explicit labels or organizational tags, unstructured data is more challenging for LLM training. However, it can also yield more general models. For instance, a model trained on a large corpus of books might learn to generate realistic prose, as is the case with GPT-3.

We’ve seen that data is at the core of LLMs, but how does this data get from its raw state to a format that an LLM can use? Let’s shift our focus to consider the key processes involved.
Data Pipelines and Ingestion for LLMs
The building blocks for acquiring and processing data for an LLM lie in the concepts of data pipelines and data ingestion.
What is a Data Pipeline?
Data pipelines form the conduit between raw, unstructured data and a fully trained LLM. They ensure that data is properly collected, processed, and prepared, making it ready for the training and validation stages of your LLM building process.
A data pipeline is a set of processes that moves data from its source to a destination where it can be stored and analyzed. Typically, this involves:
- Data extraction: Data is extracted from its source, which could be a database, a data warehouse, or even an external API.
- Data transformation: The raw data needs to be cleaned and transformed into a format that is suitable for analysis. Transformation includes handling missing values, correcting inconsistent data, converting data types, or one-hot encoding categorical variables.
- Data loading: Transformed data is loaded into a storage system, such as a database or a data warehouse. This data is then readily available for use in a machine learning model.
When we speak of data ingestion, we are referring to the front end of these pipeline processes, dealing with acquisition of data and its preparation for use.
What Does a Data Pipeline Look Like in the Context of an LLM?
While a data pipeline for an LLM may overlap generally with most pipelines used by data teams, LLMs introduce certain unique challenges to managing data for LLMs. For example:
- Data extraction: Data extraction for an LLM is often more complex, varied, and compute-heavy. Because the data sources might be websites, books, transcripts, or social media, each source has its own nuances and requires a unique approach.
- Data transformation: With such a wide range of LLM data sources, every transform step for each type of data will be different, requiring unique logic to process the data into a more standard format that an LLM can consume for training.
- Data loading: In many cases, the final step of data loading may require out-of-the-norm data storage technologies. Unstructured text data may require the use of NoSQL databases, in contrast to the relational data stores used by many data pipelines.
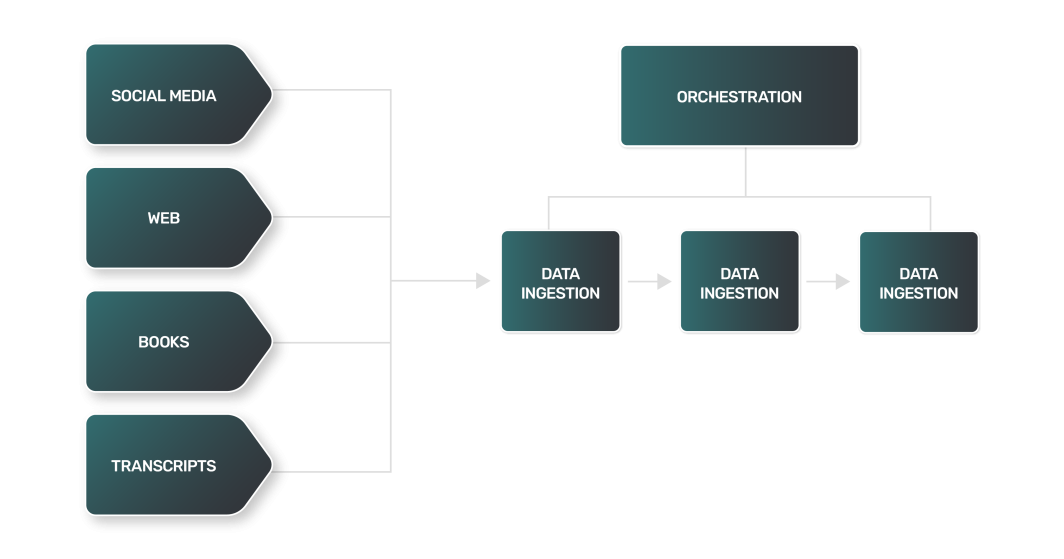
The data transformation process for LLMs includes techniques that are similar to what one would find in natural language processing (NLP):
- Tokenization: Breaking text into individual words or “tokens.”
- Stop word removal: Eliminating commonly used words like “and,” “the,” and “is.” However, depending on the task for which the LLM was trained, stop words may retained in order to preserve important syntactic and semantic information.
- Lemmatization: Reducing words to their base or root form.
As you can imagine, combining all these steps to ingest massive amounts of data from a wide range of sources can result in an incredibly complicated and large data pipeline. To help you in your task, you’ll need good tools and resources.
Common Tools Used for Data Ingestion
Several extremely popular tools in the data engineering space can help you with the complex data ingestion processes that form a part of your data pipeline. If you’re building your own LLM, the majority of your development time will be spent gathering, cleaning, and storing the data used for training. Tools to help you manage data for LLMs can be categorized as follows:
- Pipeline orchestration: Platforms to monitor and manage the processes in your data pipeline.
- Compute: Resources to process your data at scale.
- Storage: Databases to store the large amount of data required for effective LLM training.
Let’s look at each of these in more detail.
Pipeline Orchestration
Apache Airflow is a popular, open-source platform for programmatically authoring, scheduling, and monitoring data workflows. It allows you to create complex data pipelines with its Python-based coding interface, which is both versatile and easy to work with. The tasks in Airflow are organized in Directed Acyclic Graphs (DAGs), where each node represents a task, and the edges represent dependencies between the tasks.
Airflow is widely used for data extraction, transformation, and load operations, making it a valuable tool in the data ingestion process. Linode’s Marketplace offers Apache Airflow for easy setup and use.
Compute
In addition to pipeline management with tools like Airflow, you’ll need adequate computing resources that can run reliably at scale. As you ingest large amounts of textual data and perform downstream processing from many sources, your task will require compute resources that can scale—ideally, in a horizontal fashion—as necessary.
One popular choice for scalable computing is Kubernetes. Kubernetes brings flexibility and integrates well with many tools, including Airflow. By leveraging managed Kubernetes, you can spin up flexible compute resources quickly and simply.
Storage
A database is integral to the data ingestion process, serving as the primary destination for the ingested data after it has been cleaned and transformed. Various types of databases can be employed. Which type to use depends on the nature of the data and the specific requirements of your use case:
- Relational databases use a tabular structure to store and represent data. They are a good choice for data that has clear relations and where data integrity is critical. Although your LLM will depend on unstructured data, a relational database like PostgreSQL can work with unstructured data types too.
- NoSQL databases: NoSQL databases include document-oriented databases, which do not use a tabular structure to store data. They’re a good choice for handling large volumes of unstructured data, providing high performance, high availability, and easy scalability.
As an alternative to databases for storage of LLM data, some engineers prefer to use distributed file systems. Examples include AWS S3 or Hadoop. Although a distributed file system can be a good option for storing large amounts of unstructured data, it requires additional effort to organize and manage your large datasets.
For storage options from the Marketplace, you‘ll find managed PostgreSQL and managed MySQL. Both options are easy to set up and plug into your LLM data pipeline.
While it’s possible for smaller LLMs to train with less data and get away with smaller databases (such as a single PostgreSQL node), heavier use cases will work with very large amounts of data. In these cases, you’ll likely need something like a PostgreSQL Cluster to support the volume of data you’ll work with, manage data for LLMs, and to serve up that data reliably.
When choosing a database to manage data for LLMs, consider the nature of the data and the requirements of your case. The type of data you ingest will determine which kind of database is best suited for your needs. Your use case requirements—such as performance, availability, and scalability—will also be important considerations.
Ingesting data effectively and accurately is crucial for the success of an LLM. With the appropriate use of the tools, you can build reliable and efficient data ingestion processes for your pipeline, handling large amounts of data and ensuring your LLM has what it needs to learn and deliver accurate results.
To Wrap Up
The meteoric rise in popularity of LLMs has opened new doors in the tech space. The technology is readily accessible to developers, but their ability to manage data for LLMs and harness data to train new LLMs or fine-tune existing ones will dictate their long-term success.
If you’re starting work on an LLM project, you need to understand the basics before jumping into the deep end. To be most effective, an LLM requires the ingestion of a large volume of unstructured data, a process that includes extraction from sources, preprocessing, transformation, and importing. Performing these tasks requires tools like Airflow and Kubernetes for pipeline orchestration and scalable computing resources. In addition, the unstructured nature of the data commonly used for LLM training requires a data storage option such as PostgreSQL, which can be used reliably at scale through clusters.




Comments